
Model fitting#
Often, when working with experimental data, we wish to describe our many data points chemical analysis relies on our ability to fit a “line of best fit” to some data. For example, considering the determination of the activation energy, \(E_a\), of some reaction from an Arrhenius relationship,
where, \(k(T)\) is the rate constant at time \(T\), \(A\) is the pre-exponential factor, \(R\) is the ideal gas constant and \(T\) is the temperature. Typically when we are performing our analysis, we will rearrange the above equation to give a straight line,
Let’s looks at some experimental data for the decomposition of 2 moles of NO2 to 2 moles of NO and one mole of O2. The data for this is available in this file.
import numpy as np
import matplotlib.pyplot as plt
T, k = np.loadtxt('arrhenius.txt', unpack=True)
plt.plot(T, k, 'o--')
plt.xlabel('Temperature/K')
plt.ylabel('Rate constant/M$^{-1}$s$^{-1}$')
plt.show()
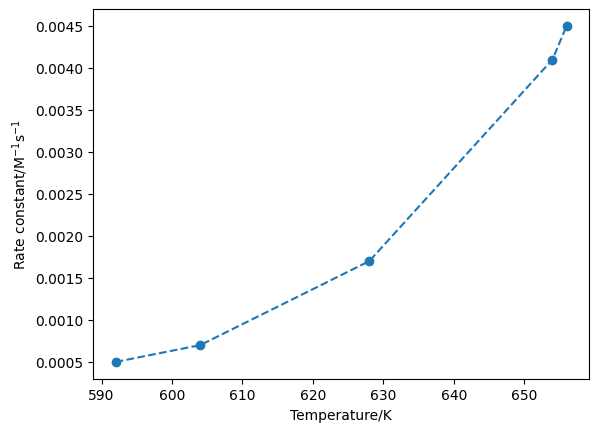
Alternatively, we plot this as a straight line.
plt.plot(1/T, np.log(k), 'o--')
plt.xlabel('1/Temperature/K')
plt.ylabel('ln(Rate constant/M$^{-1}$s$^{-1}$)')
plt.show()
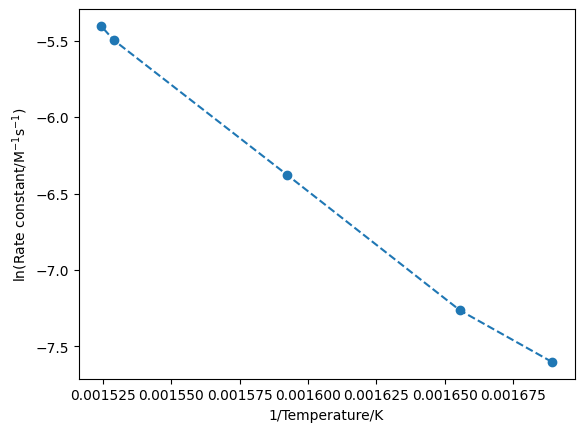
Using Python, we can fit this data in either configuration, either by performing a linear regression or by fitting a line of best fit.
Linear regression#
Linear regression is a relatively simple mathematical process, that is implemented in the scipy.stats module.
from scipy.stats import linregress
If we investigate the documentation for the linregress function, we will see that we pass two arrays; x and y.
These corresponding exactly to the x and y-axes of the plot above.
result = linregress(1/T, np.log(k))
result
LinregressResult(slope=-13509.355973303444, intercept=15.161037389899018, rvalue=-0.998952302406746, pvalue=4.070235273533486e-05, stderr=357.31270179790863, intercept_stderr=0.5715179164952109)
We can see that the object that is returned contains a couple of pieces of information.
The two parts that we are most interested in are the slope and the intercept, which are attributes of the result object and can be obtained as follows.
print(result.slope)
-13509.355973303444
print(result.intercept)
15.161037389899018
Therefore, we can evaluate the activation energy and the pre-exponential factor as follows.
from scipy.constants import R
activation_energy = - R * result.slope
preexponential_factor = np.exp(result.intercept)
print(f"A = {preexponential_factor}; E_a = {activation_energy}")
A = 3840209.1525825486; E_a = 112323.03523328649
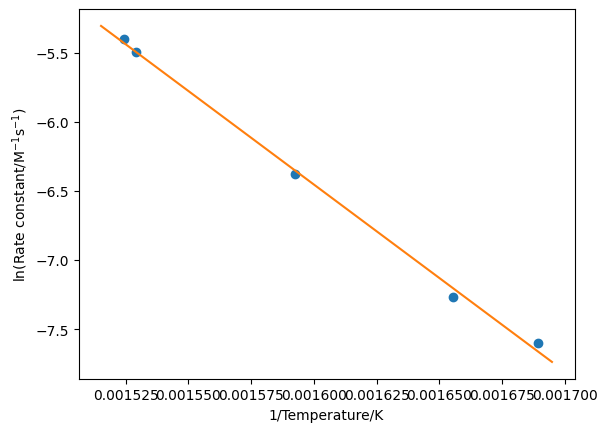
Finally, we can plot our linear regression line through the data as shown below.
x = np.linspace(1/660, 1/590, 1000)
plt.plot(1/T, np.log(k), 'o')
plt.plot(x, result.slope * x + result.intercept, '-')
plt.xlabel('1/Temperature/K')
plt.ylabel('ln(Rate constant/M$^{-1}$s$^{-1}$)')
plt.show()
Non-linear regression#
Of course, our equation cannot always be modified to offer a straight line formulation or we may not want to as the logarithmic scaling of the y-axis may skew our understanding of the intercept. Therefore, necessary to fit a non-linear relationship. This can also be achieved with Python by minimising the difference between our model (the equation with given parameters) and the data. The value that we will minimize is known as the \(\chi^2\)-value, which has the following definitions.
depending on whether or not uncertainty in the data is known.
Consider the following data, which describe the decomposition of hydrogen peroxide in the presence of excess cerous ion CeIII,
2H2O2 + 2CeIII → 2H2O + CeIV + O2.
Time/s |
2 |
4 |
6 |
8 |
10 |
12 |
14 |
16 |
18 |
20 |
|---|---|---|---|---|---|---|---|---|---|---|
[H2O2]/moldm-3 |
6.23 |
4.84 |
3.76 |
3.20 |
2.60 |
2.16 |
1.85 |
1.49 |
1.27 |
1.01 |
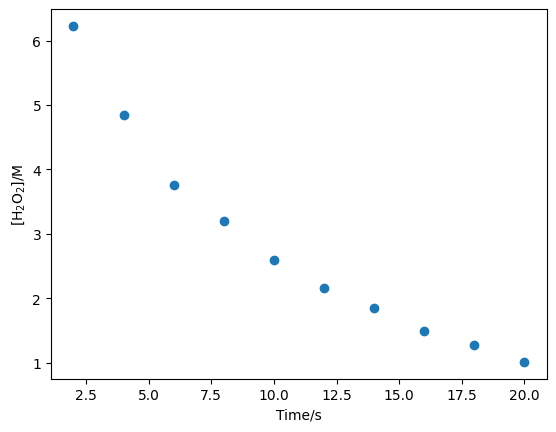
First, we will store these values as NumPy arrays.
c = np.array([6.23, 4.84, 3.76, 3.20, 2.60, 2.16, 1.85, 1.49, 1.27, 1.01])
t = np.array([2, 4, 6, 8, 10, 12, 14, 16, 18, 20])
plt.plot(t, c, 'o')
plt.xlabel('Time/s')
plt.ylabel('[H$_2$O$_2$]/M')
plt.show()
This reaction has a first-order rate equation, this will be our “model” that we will compare to the data, where the \([A]_0\) and \(k\) are the varying parameters. This function is defined below.
def first_order(t, a0, k):
"""
The first-order rate equation.
Args:
t (float): Time (s).
a0 (float): Initial concentration (mol/dm3).
k (float): Rate constant (s-1).
Returns:
(float): Concentration at time t (mol/dm3).
"""
return a0 * np.exp(-k * t)
We want to vary a0 and k to minimise the \(\chi^2\)-value between this model and the data.
def chi_squared(parameters, t, conc):
"""
Determine the chi-squared value for a first-order rate equation.
Args:
parameters (list): The variable parameters of first_order (a0 and k).
t (float): The experimental time (s) data.
conc (float): The experimental concentration data which first_order aims to model.
Returns:
(float): chi^2 value.
"""
a0 = parameters[0]
k = parameters[1]
return np.sum((conc - first_order(t, a0, k)) ** 2)
Just like the minimisation of a potential model.
We can use the scipy.optimize.minimize to minimize this chi-squared function.
from scipy.optimize import minimize
result = minimize(chi_squared, [10, 1], args=(t, c))
result
message: Optimization terminated successfully.
success: True
status: 0
fun: 0.13373044840241233
x: [ 7.422e+00 1.031e-01]
nit: 10
jac: [ 1.471e-07 2.036e-06]
hess_inv: [[ 7.888e-01 1.263e-02]
[ 1.263e-02 3.022e-04]]
nfev: 63
njev: 21
x = np.linspace(2, 20, 1000)
plt.plot(t, c, 'o')
plt.plot(x, first_order(x, result.x[0], result.x[1]))
plt.xlabel('Time/s')
plt.ylabel('[H$_2$O$_2$]/M')
plt.show()
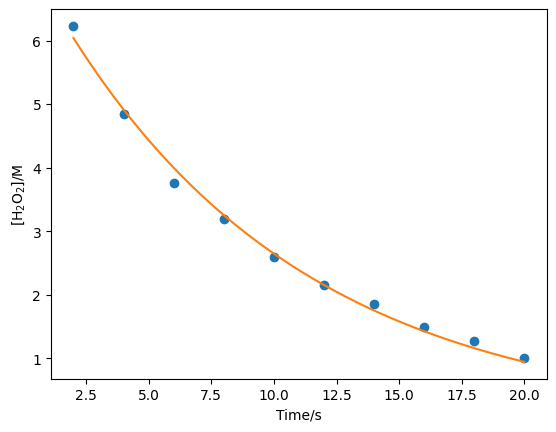
print(f"[A]_0 = {result.x[0]}; k = {result.x[1]}")
[A]_0 = 7.421644149462027; k = 0.10308255587972329
scipy.optimize.curve_fit offers a convenient wrapper around this methodology, and makes it easy to access the estimated parameter uncertainties.
from scipy.optimize import curve_fit
popt, pcov = curve_fit(first_order, t, c)
/tmp/ipykernel_2456/2319394663.py:13: RuntimeWarning: overflow encountered in exp
return a0 * np.exp(-k * t)
We can ignore the above error, this is just warning that during the optimization an unphysical value was found.
However, the curve_fit function is robust enough to ignore this and continue.
uncertainties = np.sqrt(pcov)
print(f"[A]_0 = {popt[0]} +/- {uncertainties[0][0]}; k = {popt[1]} +/- {uncertainties[1][1]}")
[A]_0 = 7.42164476326434 +/- 0.1583887665748318; k = 0.10308257141927114 +/- 0.0030883676626833898